时至今日,你对混合云是不是还有什么误解?
2006年8月,被定义为“互联网第三次革命”的云计算首次闯入了人们的视野。在此后发展的十多年间,无论是颠覆我们生活的互联网企业,还是积极拥抱变化的传统行业,都将云计算作为流程和业务创新的“抓手”,纷纷“上云”。
对象存储是云存储的一部分,它提供了云存储后端的存储服务。云存储是建立在对象存储之上的一个整体的解决方案,除了后端的存储服务之外,它还需要包括各种操作系统和平台上运行的客户端、身份认证、多种管理和监控功能等。
本书主要集中在对象存储的原理架构和实现上,对云存储其他组件也会有一定的介绍,但不会是本书的主要内容。
分布式存储的好处
传统的高端服务器性能强劲、成本高昂,以前只有大公司用来搭建自己的私有存储。互联网生态下的云存储则用数量弥补质量,以大量低成本的普通PC服务器组成网络集群来提供服务。相比传统的高端服务器来说,同样价格下分布式存储提供的服务更好、性价比更高,且新节点的扩展以及坏旧节点的替换更为方便。
1.1和传统网络存储的区别
要理解对象存储,我们首先要来谈谈传统的网络存储。传统的网络存储主要有两类,分别是NAS和SAN。
NAS是Network Attached Storage的简称,是一个提供了存储功能和文件系统的网络服务器。客户端可以访问NAS上的文件系统,还可以上传和下载文件。NAS客户端和服务端之间使用的协议有SMB、NFS以及AFS等网络文件系统协议。对于客户端来说,NAS就是一个网络上的文件服务器。
SAN是Storage Area Network的简称。它和NAS的区别是SAN只提供了块存储,而把文件系统的抽象交给客户端来管理。SAN的客户端和服务端之间的协议有Fibre Channel、iSCSI、ATA over Ethernet(AoE)和HyperSCSI。对于客户端来说,SAN就是一块磁盘,可以对其格式化、创建文件系统并挂载。
NAS和SAN并不是完全对立的,现代的网络存储通常都是两者混合使用,可以同时提供文件级别的协议和块级别的协议。
介绍完传统的网络存储,那么对象存储跟它们又有什么区别呢?首先是对数据的管理方式不同。
1.1.1数据的管理方式
对于网络文件系统来说,数据是以一个个文件的形式来管理的;对于块存储来说,数据是以数据块的形式来管理的,每个数据块有它自己的地址,但是没有额外的背景信息;对象存储则是以对象的方式来管理数据的,一个对象通常包含了3个部分:对象的数据、对象的元数据以及一个全局唯一的标识符(即对象的ID)。
对象的数据就是该对象中存储的数据本身。一个对象可以用来保存大量无结构的数据,比如一首歌、一张照片或是一个在线文档。
对象的元数据是对象的描述信息,为了和对象的数据本身区分开来,我们称其为元数据。比如某首歌的歌名、某张照片拍摄的时间、某个文档的大小等都属于描述信息,也就是元数据。对于对象的元数据,我们在第3章会详细介绍,这里不多展开。
对象的标识符用于引用该对象。和对象的名字不同,标识符具有全局唯一性。名字不具有这个特性,例如张三家的猫名字叫阿黄,李四家的狗名字也可以叫阿黄,名字为阿黄的对象可以有很多个。但若是用标识符来引用就只可能有一个。
除了对数据的管理方式不同以外,对象存储跟网络存储访问数据的方式也不同。
1.1.2访问数据的方式
网络文件系统的客户端通过NFS等网络协议访问某个远程服务器上存储的文件。块存储的客户端通过数据块的地址访问SAN上的数据块。对象存储则通过REST网络服务访问对象。
REST是Representational State Transfer的简称。REST网络服务通过标准HTTP服务对网络资源提供一套预先定义的无状态操作。在万维网刚兴起的时候,网络资源被定义为可以通过URL访问的文档或文件。现如今对于它的定义已经更为宽泛和抽象:网络上一切可以通过任何方式被标识、命名、引用或处理的东西都是一种网络资源。对于对象存储来说,对象当然就是一种网络资源,但除了对象本身以外,我们也需要提供一些其他的网络资源用来访问对象存储的各种功能,本书后续会一一介绍。
客户端向REST网络服务发起请求并接收响应,以确认网络资源发生了某种变化。HTTP预定义的请求方法(Request Method)通常包括且不限于GET、POST、PUT、DELETE等,它们分别对应不同的处理方式:GET方法在REST标准中通常用来获取某个网络资源;PUT通常用于创建或替换某个网络资源(注意,它跟PUT的区别是POST一般不同于替换网络资源,如果该资源已经存在,POST通常会返回一个错误而不是覆盖它);POST通常用于创建某个网络资源,DELETE通常用于删除某个网络资源。
我们会在本书的后续章节看到对象存储的接口是如何使用这些HTTP请求方法的。
1.1.3对象存储的优势
对象存储首先提升了存储系统的扩展性。当一个存储系统中保存的数据越来越多时,存储系统也需要同步扩展,然而由于存储架构的硬性限制,传统网络存储系统的管理开销会呈指数上升。而对象存储架构的扩展只需要添加新的存储节点就可以。
对象存储的另一大优势在于以更低的代价提供了数据冗余的能力。在分布式对象存储系统中一个或多个节点失效的情况下,对象依然可用,且大多数情况下客户都不会意识到有节点出了问题。传统网络存储对于数据冗余通常采用的方式是保留多个副本(一般至少3份,这样当其中一个副本出了错,我们还能用少数服从多数的方式解决争议),而对象存储的冗余效率则更高。我们会在第5章讨论数据冗余的问题。
本文将要实现的是一个单机版的对象存储原型,目的是让读者对我们讨论的对象存储有一个直观的了解。一个单机版的服务程序还称不上分布式服务,但是我们可以借此了解对象存储的接口,也就是说我们将了解客户端是如何通过REST接口上传和下载一个对象的,以及这个对象又是以什么样的形式被保存在服务器端的。从下一章开始,我们还将不断丰富架构和功能来适应各种新的需求。
1.2单机版对象存储的架构
在一台服务器上运行了一个HTTP服务提供的REST接口,该服务通过访问本地磁盘来进行对象的存取,见图1-1。
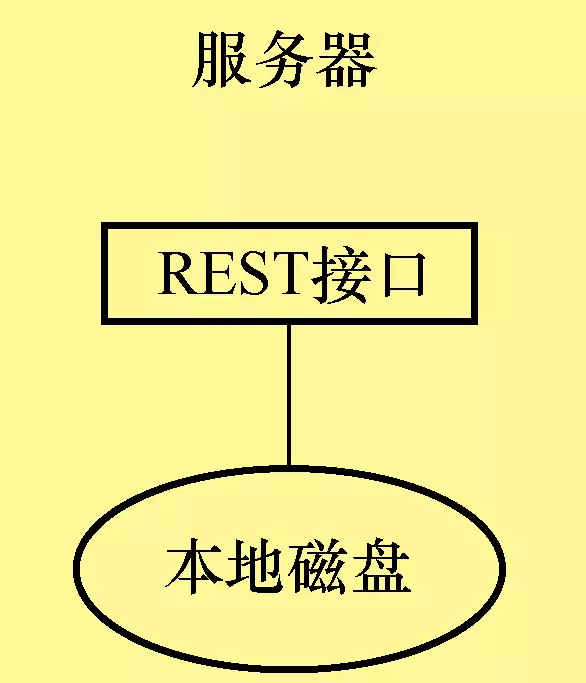
图1-1单机版对象存储的架构
1.2.1REST接口
单机版的REST接口极其简单,只实现了对象的PUT和GET方法。

请求正文(Request Body)
客户端通过PUT方法将一个对象上传至服务器,服务器则将该对象保存在本地磁盘上。
这里/objects/<object_name>是标识该对象网络资源的URL。URL是Uniform Resource Locator的简称,也就是一个网络地址,用于引用某个网络资源在网络上的位置。
在对象存储中,通常使用PUT方法来上传一个对象。

响应正文(Response Body)
客户端通过GET方法从服务器上下载一个对象,服务器在本地磁盘上查找并读取该对象,如果该对象不存在,则服务器返回HTTP错误代码404 Not Found。
在对象存储中,总是使用GET方法来下载一个对象。
1.2.2对象PUT流程
我们可以用一张简单的图来概括PUT流程,见图1-2。

图1-2单机版对象PUT流程
客户端的PUT请求提供了对象的名字<object_name>和对象的数据<content of object>,它们最终被保存在本地磁盘上的文件$STORAGE_ROOT/objects/<object_name>中。$STORAGE_ROOT环境变量保存着我们在本地磁盘上的存储根目录的名字。
1.2.3对象GET流程
对象GET流程见图1-3。
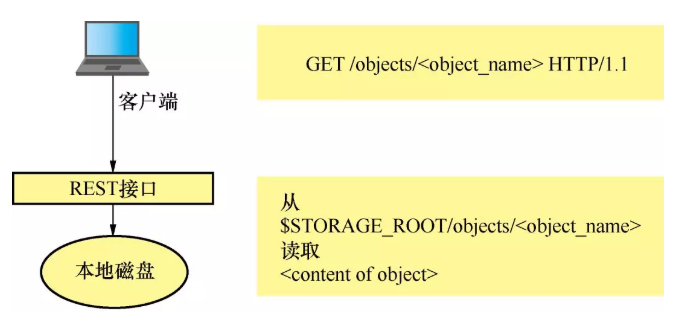
图1-3单机版对象GET流程
客户端的GET请求提供了<object_name>,我们的服务进程从本地磁盘上的文件$STORAGE_ ROOT/objects/<object_name>中读取对象并将其写入HTTP响应正文。
流程介绍完了,接下来让我们去看一下如何用Go语言实现这样一个服务。
1.3Go语言实现
首先让我们来看一下main函数的实现。和大多数语言一样,Go语言也有一个main函数作为系统的入口点。在main函数中我们需要做的只是注册一个HTTP处理函数并开始监听端口,见例1-1。
例1-1 main函数

http.HandleFunc的作用是注册HTTP处理函数objects.Handler,如果有客户端访问本机的HTTP服务且URL以“/objects/”开头,那么该请求将由objects.Handler负责处理。除此以外的HTTP请求会默认返回HTTP错误代码404 Not Found。
处理函数注册成功后,我们调用http.ListenAndServe正式开始监听端口,该端口由系统环境变量LISTEN_ADDRESS定义。正常情况下该函数永远不会返回,程序运行后会始终监听端口上的请求,除非我们发送信号中断进程。非正常情况下,该函数会将错误返回,此时log.Fatal会打印错误的信息并退出程序。
objects.Handler函数属于objects包,该包一共有3个函数,除了Handler以外还有put和get函数。在Go语言中,某个变量或函数名的首字母大写,则意味着该变量或函数可在包外部被引用;如果是首字母小写,则意味着该变量或函数名仅可在包内部被引用。Handler函数的首字母H大写就表明该函数可以在objects包外部被调用(被main包的main函数调用),而put和get函数则仅在objects包内部可见。Handler函数见例1-2。
例1-2 objects.Handler函数
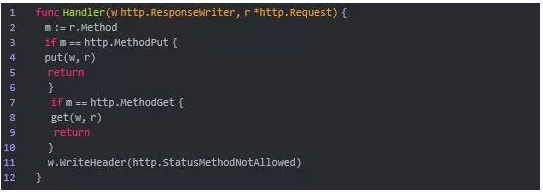
Handler有两个参数。w的类型是http.ResponseWriter,用于写入HTTP的响应。它的WriteHeader方法用于写HTTP响应的错误代码,它的Write方法则用于写HTTP响应的正文。r的类型是*http.Request,是一个指向http.Request结构体的指针,代表当前处理的HTTP的请求。它的Method成员变量记录了该HTTP请求的方法。
Handler函数会首先检查HTTP请求的方法:如果是PUT,则调用put函数;如果是GET,则调用get函数;两者皆否,则返回HTTP错误代码405 Method Not Allowed。
put函数负责处理HTTP的PUT请求,将PUT上来的对象存储在本地硬盘上,见例1-3。
例1-3 objects.put函数

put函数首先获取URL中<object_name>的部分,r.URL成员变量记录了HTTP请求的URL,它的EscapedPath方法用于获取经过转义以后的路径部分,该路径的形式是/objects/<object_name>
strings.Split函数的功能是用分隔符将一个字符串分割成多个字符串,它有两个输入变量,第一个输入变量是需要分割的字符串,第二个输入变量则是分隔符,分割后的结果以字符串的数组形式返回。在这里,strings.Split会将我们的URL路径拆分成3个字符串,分别是“”“objects”和<object_name>。所以数组的第三个元素就是<object_name>。
然后我们会调用os.Create在本地文件系统的根存储目录的objects子目录下创建一个同名文件f(根存储目录由系统环境变量STORAGE_ROOT定义。除了objects子目录以外,还有一些其他的子目录,我们还会在后续章节看到它们的用处)。如果创建失败则返回HTTP错误代码500;如果创建成功则将r.Body用io.Copy写入文件f。io.Copy接收两个参数,第一个参数是用于写入的io.Writer,在这里我们的文件f就是一个io.Writer,任何写入f的数据都会被写入f所代表的文件;io.Copy接收的第二个参数则是一个用于读取的io.Reader,在这里就是r.Body。http.Request的Body成员变量是一个io.Reader,用来读取HTTP请求的正文内容。
这里需要提醒一点:我们的实现代码默认用户提供的URL的<object_name>部分不能包含“/”,如果包含,则“/”后的部分将被丢弃。真实生产环境中的代码需要对用户的所有输入都进行严格的校验,如果用户输入的URL不符合我们的预期,则服务器必须返回一个错误的信息,而不是忽略。
细心的读者看到这里可能要问:那如果我的对象名字里就需要有一个“/”怎么办呢?别担心,任何对象名字在被放入URL之前都需要在客户端进行URL编码。在编码时,一些不适合放入URL的字符会被转义。比如说用户有一个对象名字是“C:/中文目录/a&c.txt”,编码后的名字是“C%3A%2F%E4%B8%AD%E6%96%87%E7%9B% AE%E5%BD%95%2Fa%5Cb%26c.txt”,其中的“/”被转义成“%2F”。然后客户端会以“/objects/ C%3A%2F%E4%B8%AD%E6%96%87%E7%9B%AE%E5%BD%95%2Fa% 5Cb%26c.txt”作为HTTP请求的URL访问我们的服务。我们在获取URL时使用的r.URL.EscapedPath方法得到的就是这个字符串。
get函数负责处理HTTP的GET请求,从本地硬盘上读取内容并将其作为HTTP的响应输出,见例1-4。
例1-4 objects.get函数
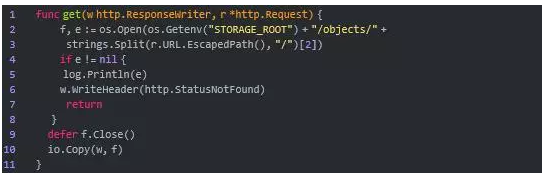
和put函数类似,get函数首先获取<object_name>并调用os.Open尝试打开本地文件系统根存储目录objects子目录中的同名文件f,如果打开失败,则返回HTTP错误代码404;如果打开成功,则用io.Copy将f的内容写入w,此时f作为读取内容的io.Reader,而w则作为写入的io.Writer。
你可能会觉得诧异,刚才我们介绍put的时候还说f是一个io.Writer,现在怎么又变成了io.Reader?事实上f本身的类型是*os.File,一个指向os.File结构体的指针。os.File这个结构体同时实现了io.Writer和io.Reader这两个接口(Go语言中称为interface)。在Go语言中,实现接口只需要实现该接口所要求的全部方法,io.Write接口只要求实现一个Write方法,而io.Read接口则只要求实现一个Read方法。os.File同时实现了Write和Read方法,于是它既是一个io.Writer也是一个io.Reader。http.ResponseWriter也是一个接口,这个接口除了实现了WriteHeader方法以外也实现了Write方法,所以它也是一个io.Write接口。
Go语言的实现介绍完了,接下来我们需要把程序运行起来,并进行功能测试来验证我们的实现。
1.4功能测试
我们需要先运行服务器程序。

别忘了在存储根目录/tmp下创建相应的objects子目录。
![]()
接下来我们用curl命令作为客户端来访问服务器,试图GET一个名为test的对象。

很好,服务器给出了预期的404错误,因为我们还从来没有PUT过一个叫test的对象。
那么,接下来我们PUT一个test对象。
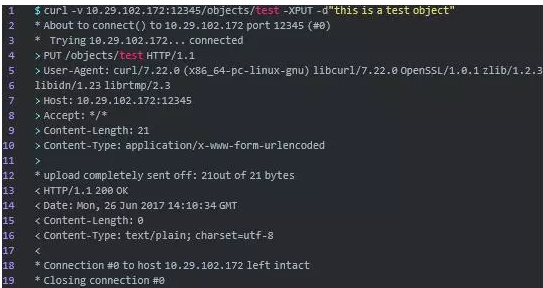
我们用curl命令PUT了一个名为test的对象,该对象的内容为“this is a test object”。服务器返回“200 OK”表示PUT成功。接下来让我们再次GET这个test对象。
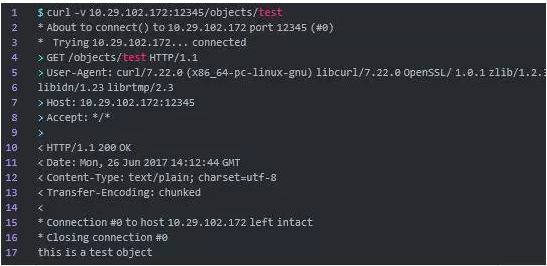
太棒了!我们成功获取了之前PUT上去的那个对象的内容。
1.5小结
我们在本文实现了一个单机版的对象存储服务,它提供了对象的PUT和GET方法。当客户端以PUT方法访问我们的服务时,客户端会提供对象的名字和内容,我们的服务就可以把对象的内容以文件的形式存储在服务器的本地磁盘上;当客户端以GET方法访问我们的服务时,我们就可以从服务器的本地磁盘上读取文件的内容并将其作为HTTP的响应输出。
这样一个单机的对象存储服务离我们最终要实现的版本还很远,它只是一个热身,让我们熟悉一下使用的方式。我们最终的目标是要实现一个云版本的对象存储。那么,相比一个云版本的对象存储来说,目前的单机版最大的问题是什么呢?
答案是可扩展性!
分布式对象存储服务必须是可扩展的,当现有的服务器集群无法满足容量、吞吐量、时延等性能指标时,我们必须能够轻易扩展现有的服务器集群。在单机版的架构中,接口和数据存储被紧紧耦合在一起,服务器只能访问本地磁盘。当一台服务器无法满足日益增长的HTTP客户端请求数量时,我们将无法通过加入一个新的服务器来扩展集群,因为新的服务器无法访问旧服务器的磁盘。
转载请注明:小猪云服务器租用推荐 » :分布式对象存储和云存储的关系