jQuery使用fetch详解
浏览器现在支持Fetch API,可以无须其他库就能实现Ajax,本文详解jQuery使用fetch
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
Kafka架构图
一、利用 Apache Kafka 系统架构的设计思路
1、网络游戏
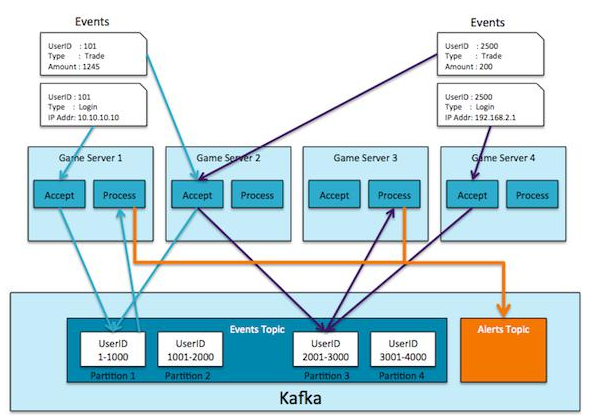
假设我们正在开发一个在线网络游戏平台,这个平台需要支持大量的在线用户实时操作,玩家在一个虚拟的世界里通过互相协作的方式一起完成每一个任务。由于游戏当中允许玩家互相交易金币、道具,我们必须确保玩家之间的诚信关系,而为了确保玩家之间的诚信及账户安全,我们需要对玩家的 IP 地址进行追踪,当出现一个长期固定 IP 地址忽然之间出现异动情况,我们要能够预警,同时,如果出现玩家所持有的金币、道具出现重大变更的情况,也要能够及时预警。此外,为了让开发组的数据工程师能够测试新的算法,我们要允许这些玩家数据进入到 Hadoop 集群,即加载这些数据到 Hadoop 集群里面。
对于一个实时游戏,我们必须要做到对存储在服务器内存中的数据进行快速处理,这样可以帮助实时地发出预警等各类动作。我们的系统架设拥有多台服务器,内存中的数据包括了每一个在线玩家近 30 次访问的各类记录,包括道具、交易信息等等,并且这些数据跨服务器存储。
我们的服务器拥有两个角色:首先是接受用户发起的动作,例如交易请求,其次是实时地处理用户发起的交易并根据交易信息发起必要的预警动作。为了保证快速、实时地处理数据,我们需要在每一台机器的内存中保留历史交易信息,这意味着我们必须在服务器之间传递数据,即使接收用户请求的这台机器没有该用户的交易信息。为了保证角色的松耦合,我们使用 Kafka 在服务器之间传递信息 (数据)。
2、Kafka 特性
Kafka 的几个特性非常满足我们的需求:可扩展性、数据分区、低延迟、处理大量不同消费者的能力。这个案例我们可以配置在 Kafka 中为登陆和交易配置同一个主题。由于 Kafka 支持在单一主题内的排序,而不是跨主题的排序,所以我们为了保证用户在交易前使用实际的 IP 地址登陆系统,我们采用了同一个主题来存储登陆信息和交易信息。
当用户登陆或者发起交易动作后,负责接收的服务器立即发事件给 Kafka。这里我们采用用户 id 作为消息的主键,具体事件作为值。这保证了同一个用户的所有的交易信息和登陆信息被发送到 Kafka 分区。每一个事件处理服务被当作一个 Kafka 消费者来运行,所有的消费者被配置到了同一个消费者群组,这样每一台服务器从一些 Kafka 分区读取数据,一个分区的所有数据被送到同一个事件处理服务器 (可以与接收服务器不同)。当事件处理服务器从 Kafka 读取了用户交易信息,它可以把该信息加入到保存在本地内存中的历史信息列表里面,这样可以保证事件处理服务器在本地内存中调用用户的历史信息并做出预警,而不需要额外的网络或磁盘开销。
二、Kafka服务安装
了解了Kafka一些很基础的概念后,还是需要动手去体验它是如何操作的。下面是在CentOS7的一些安装过程。
1、服务文件下载
可在Kafka的官网http://kafka.apache.org/下载最新的资源文件
2、修改配置
主要需要修改的配置文件有:server.properties,配置文件kafka目录下的配置文件夹下。
修改内容如下:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers.
advertised.listeners=PLAINTEXT://:9092
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
简单的说明
listeners配置服务监控的套接字的地址
advertised.listeners配置收件人通知的生产者和消费者的主机名和端口
log.dirs配置消息数据存储的目录
3、启动服务
Kafka使用的是1.1.0的版本,内部自带了Zookeeper那么就不需要额外的下载Zookeeper了。
3.1首先启动Zookeeper服务
nohup ./bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper.log &
3.2启动Kafka服务
nohup ./bin/kafka-server-start.sh config/server.properties > kafka.log &
简单提一下,nohup和&是为了让Zookeeper和Kafka的服务能够在后台运行,并执行命令输出的日志分别记录到对应文件中去;
转载请注明:小猪云服务器租用推荐 » kafka是什么?如何下载部署呢?