让面试官瞠目结舌的数据库优化技术!(上)
本文主要是针对Mysql进行举例,如果想要看oracle的小伙伴恐怕要失望了,不过看本文能促进您对通用数据库技术的理解。
有时候公众号文章需要进行整理分析,要把所有文章的链接整合起来还真不是一个容易的事情!手动整理固然简单,但文章数量多起来整理还真不是一件容易的事情。
这个时候我们可以用到神器Python,定制爬虫的指定“装备”!
我们知道,微信公众号的文章链接都是做了隐藏的,一般爬虫无法抓取,我们应该怎么办呢?
没有真实链接
我们需要通过抓包提取公众号文章的请求的 URL,此次我们以Charles为例子,勾选抓取电脑请求, 默认就是勾选的,不改动即可!
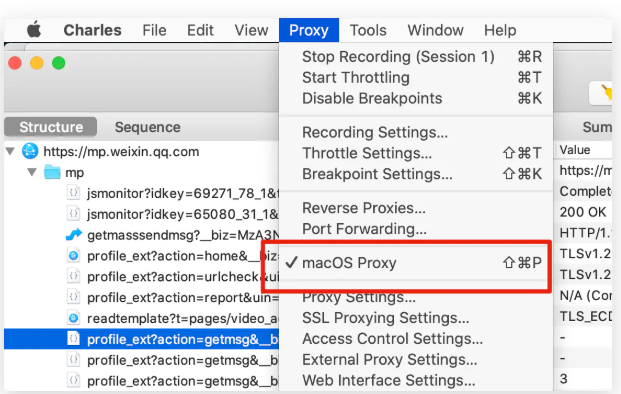
默认勾选
过滤掉无关请求,我们指抓取微信的域名,可以在软件下方设置要抓取的域名具体如图所示!
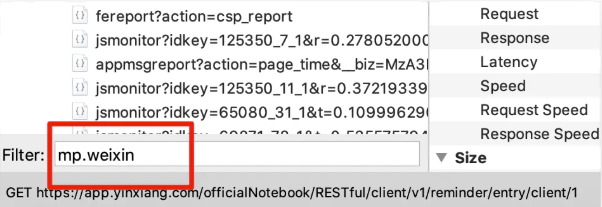
微信mp开头的域名
打开“云”的微信公众号的文章列表后,Charles 就会抓取到大量的请求,找到我们需要的文章标题与链接,在JSON返回的信息里面包含了文章的标题、链接、信息等等。
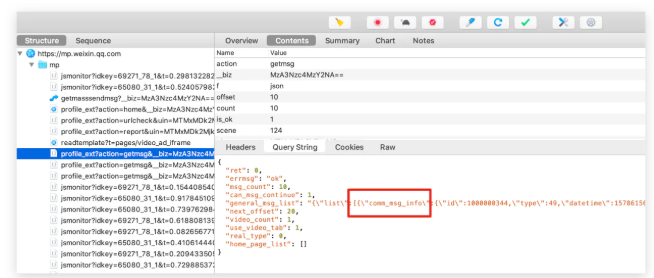
返回文章标题与链接
这些都是请求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
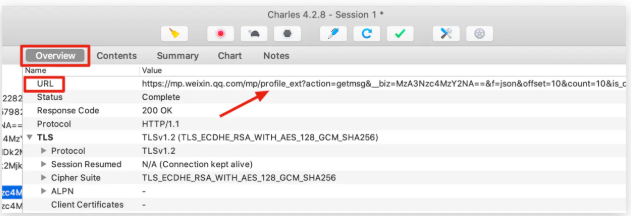
Overview
抓包抓到这么多,下面我们就可以进行对标题与链接的提取了!
初始化函数
我们通过对抓包的信息进行分析后,则可以使用requests 库来进行请求,对返回的值进行判断!如果返回是是整形200则说明一切正常,我们再构建parse_data()函数来进行解析我们所需要的信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过刚才Json的分析,我们则能看到需求的数据均在appmsgext_info 下面。
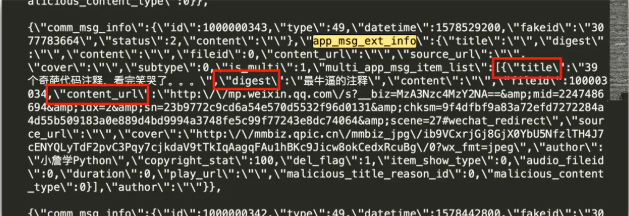
提取数据
我们用 json.loads 解析返回的 Json 信息,把我们需要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas[‘ret’] and all_datas[‘msg_count’]>0:
summy_datas = all_datas[‘general_msg_list’]
datas = json.loads(summy_datas)[‘list’]
a = []
for data in datas:
try:
title = data[‘app_msg_ext_info’][‘title’]
title_child = data[‘app_msg_ext_info’][‘digest’]
article_url = data[‘app_msg_ext_info’][‘content_url’]
info = {}
info[‘标题’] = title
info[‘小标题’] = title_child
info[‘文章链接’] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print(‘正在写入文件’)
with open(‘Python公众号文章合集1.csv’, ‘a’, newline=”, encoding=’utf-8′) as f:
fieldnames = [‘标题’, ‘小标题’, ‘文章链接’] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print(“写入成功”)
print(‘—————————————-‘)
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print(‘抓取数据完毕!’)
进行以上操作后,我们抓取的数据则会以csv 格式保存起来。
注意:运行代码时,可能会遇到 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
文字工作者应该知道,一般文章都会保存为markdown格式,因为这样不管我们把整理好的文章放到哪个平台其格式是不会变化的。在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
d_url = ‘[{}]’.format(title) + ‘({})’.format(article_url)
当爬虫运行完毕后,则效果如下:
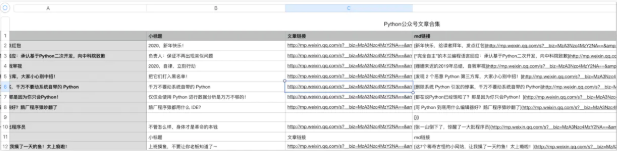
结果展示
剩下的就是整合分类的问题了,这就要看你自己喽!
在云服务器中部署爬虫更快更便捷哦!
转载请注明:小猪云服务器租用推荐 » 整理公众号文章?Python爬虫让一切变的简单……